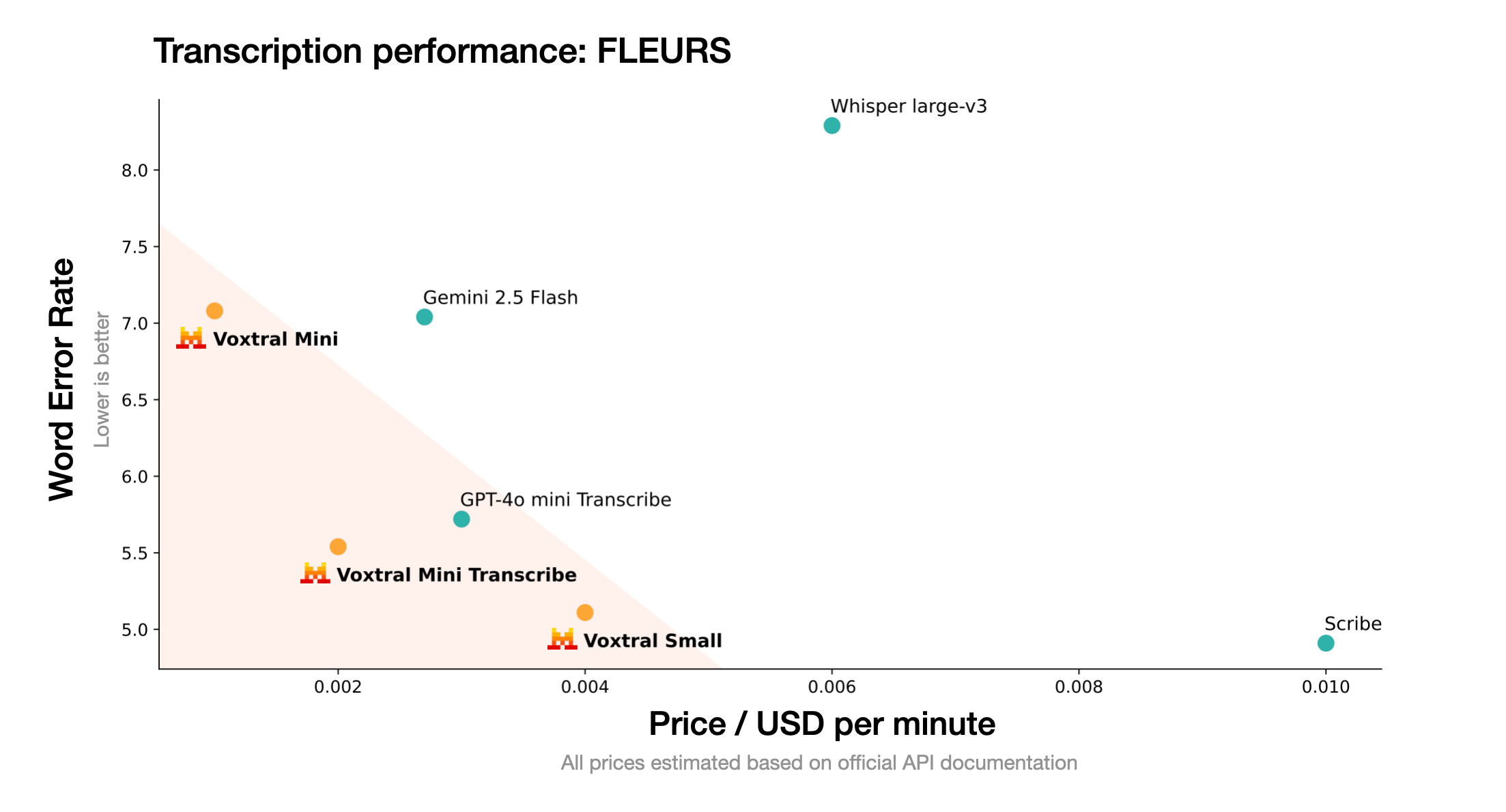
Voxtral
综合介绍
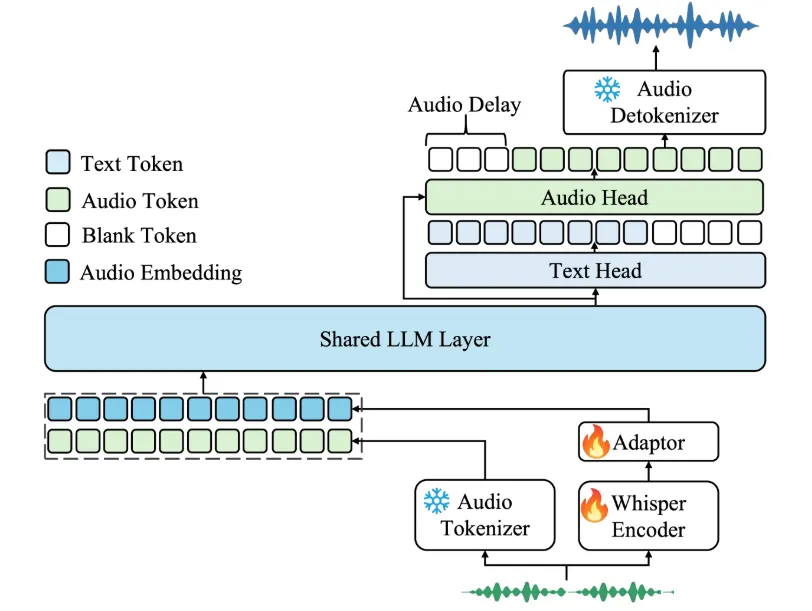
Voxtral是Mistral AI开发的一系列先进的语音理解模型。 它将顶尖的语音识别功能与强大的语言理解能力相结合,旨在提供一个更加自然、高效的人机交互界面。 Voxtral系列模型是开源的,使用Apache 2.0许可证发布,为开发者和企业提供了灵活的部署选项。 该系列目前包含两个不同规模的模型:一个是240亿参数的Voxtral Small版本,适用于需要大规模处理的生产环境;另一个是30亿参数的Voxtral Mini版本,专门为本地和边缘计算设备优化。 这些模型不仅能完成高精度的语音转文字任务,还能直接对音频内容进行问答、生成摘要和执行函数调用。 它们原生支持多种语言,包括英语、西班牙语、法语、德语等,并能自动检测语言,非常适合需要服务全球用户的应用场景。
功能列表
- 高精度语音转录:能够将语音内容准确转换为文字,在多项行业基准测试中表现出色。
- 原生多语言支持:无需额外配置即可自动识别并处理多种常用语言,如英语、中文、西班牙语、法语、德语、印地语等。
- 长音频处理:支持长达32k令牌的上下文窗口,可以处理最长30分钟的音频转录或40分钟的音频理解任务。
- 内置音频理解:可以直接对音频内容进行提问和回答,或生成结构化的摘要,无需将语音识别(ASR)和语言模型分开处理。
- 语音函数调用:允许通过语音指令直接触发后端程序、工作流或API调用,将语音交互转化为可操作的系统命令。
- 强大的文本处理能力:继承了其基础语言模型(如Mistral Small 3.1)的文本理解能力,也可以作为相应的文本模型直接使用。
- 灵活的部署选项:提供适用于云端生产环境的24B模型和适用于边缘计算的3B模型,同时支持通过API或本地部署使用。
- 开源许可:所有模型均在Apache 2.0许可下发布,允许用户自由使用和修改。
使用帮助
Voxtral模型提供了极大的灵活性,用户可以根据自己的需求选择通过vLLM或Hugging Face Transformers库在本地运行,也可以直接使用Mistral AI提供的API服务。以下是详细的使用说明,主要介绍如何在本地环境中部署和使用Voxtral模型。
准备工作
在开始之前,请确保您的开发环境中已经安装了Python,并拥有一张或多张性能足够的NVIDIA GPU。Voxtral Mini (3B) 模型大约需要9.5 GB的GPU显存,而Voxtral Small (24B) 模型则需要约55 GB的显存。
方法一:使用vLLM进行部署(推荐)
vLLM是一个高性能的LLM推理和服务引擎,Mistral AI官方推荐使用此方法以获得最佳性能。
1. 安装vLLM及相关依赖为了确保能使用Voxtral的音频功能,你需要从"main"分支安装vLLM,并包含音频处理的相关依赖。推荐使用uv进行安装:
uv pip install -U "vllm找不到条目。
" --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
安装完成后,需要检查mistral_common库的版本是否大于等于1.8.1,因为该库包含了处理音频和文本所需的重要工具。
python -c "import mistral_common; print(mistral_common.__version__)"```
**2. 启动vLLM服务**
安装完成后,您可以启动一个HTTP服务来提供模型推理接口。以`Voxtral-Mini-3B-2507`为例:
```bash
vllm serve mistralai/Voxtral-Mini-3B-2507 --tokenizer_mode mistral --config_format mistral --load_format mistral
对于参数量更大的Voxtral-Small-24B-2507模型,您可能需要使用多张GPU,并通过--tensor-parallel-size参数指定并行数量。例如,使用两张GPU:
vllm serve mistralai/Voxtral-Small-24B-2507 --tokenizer_mode mistral --config_format mistral --load_format mistral --tensor-parallel-size 2 --tool-call-parser mistral --enable-auto-tool-choice
3. 与模型进行交互(客户端)服务启动后,您可以使用openai Python库来调用vLLM提供的API。
首先,安装客户端所需的库:
pip install --upgrade "mistral_common找不到条目。
" openai
示例:音频问答下面的代码展示了如何向模型提交两个音频文件和一个文本问题,让模型比较两个音频中的发言者。
from mistral_common.protocol.instruct.messages import TextChunk, AudioChunk, UserMessage
from mistral_common.audio import Audio
from huggingface_hub import hf_hub_download
from openai import OpenAI
# 配置vLLM服务的地址
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1" # 请替换为您的服务地址
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
# 获取模型ID
model_id = client.models.list().data[0].id
# 下载示例音频文件
obama_file = hf_hub_download("patrickvonplaten/audio_samples", "obama.mp3", repo_type="dataset")
bcn_file = hf_hub_download("patrickvonplaten/audio_samples", "bcn_weather.mp3", repo_type="dataset")
# 将音频文件转换为模型可接受的格式
def file_to_chunk(file: str) -> AudioChunk:
audio = Audio.from_file(file, strict=False)
return AudioChunk.from_audio(audio)
# 构建用户消息,包含音频和文本
text_chunk = TextChunk(text="Which speaker is more inspiring? Why? How are they different from each other?")
user_msg = UserMessage(content=[file_to_chunk(obama_file), file_to_chunk(bcn_file), text_chunk])
# 发送请求
response = client.chat.completions.create(
model=model_id,
messages=[user_msg.to_openai()],
temperature=0.2,
top_p=0.95,
)
print(response.choices[0].message.content)```
### **方法二:使用Hugging Face Transformers库**
如果您更熟悉Hugging Face生态,可以直接使用`transformers`库进行推理。
**1. 安装依赖**
首先,需要从源代码安装最新版本的`transformers`库,并确保`mistral_common`已安装并包含音频依赖。
```bash
pip install git+https://github.com/huggingface/transformers
pip install --upgrade "mistral-common找不到条目。
"
2. 使用示例transformers库提供了简洁的API来处理复杂的输入。
示例:多模态对话(音频+文本)以下代码展示了如何将两个音频文件和一个文本问题组合成一个对话回合,并获取模型的回答。
from transformers import VoxtralForConditionalGeneration, AutoProcessor
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
repo_id = "mistralai/Voxtral-Mini-3B-2507" # 或使用 'mistralai/Voxtral-Small-24B-2507'
processor = AutoProcessor.from_pretrained(repo_id)
model = VoxtralForConditionalGeneration.from_pretrained(
repo_id,
torch_dtype=torch.bfloat16, # 使用bfloat16以节省显存
device_map=device
)
# 构建对话内容,包含音频文件的URL或本地路径
conversation = [
{
"role": "user",
"content": [
{ "type": "audio", "path": "https://huggingface.co/datasets/hf-internal-testing/dummy-audio-samples/resolve/main/mary_had_lamb.mp3" },
{ "type": "audio", "path": "https://huggingface.co/datasets/hf-internal-testing/dummy-audio-samples/resolve/main/winning_call.mp3" },
{ "type": "text", "text": "What sport and what nursery rhyme are referenced?" },
],
}
]
# 使用processor处理输入
inputs = processor.apply_chat_template(conversation, return_tensors="pt").to(device, dtype=torch.bfloat16)
# 生成回复
outputs = model.generate(**inputs, max_new_tokens=500)
# 解码输出
decoded_outputs = processor.batch_decode(outputs[:, inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(decoded_outputs[0])
这个框架同样支持纯文本、纯音频、多轮对话等多种场景,只需相应地调整conversation列表的结构即可。
应用场景
- 智能客服中心利用Voxtral对客户的语音通话进行实时转录和分析,自动识别客户意图、提取关键信息(如订单号、问题类型),并进行情感分析。 这可以帮助客服代表更快地理解客户需求,并为后续的数据分析和服务改进提供结构化的数据。
- 会议转录与摘要Voxtral可以处理长达30分钟的会议录音,生成准确的文字记录。 更进一步,它还能根据会议内容自动生成摘要、提炼关键决策点和待办事项,极大地提高了会议后整理工作的效率。
- 语音助手和智能家居在边缘设备上部署Voxtral Mini模型,可以打造响应迅速且无需联网的语音助手。 用户可以通过语音指令查询信息、控制家电(通过函数调用功能)或进行日常对话,所有数据处理都在本地完成,保障了用户隐私。
- 内容创作与媒体处理媒体行业的从业者可以使用Voxtral为视频快速生成字幕,或将采访录音转换为文字稿。 其多语言能力使其能够轻松处理来自不同国家和地区的音频素材,拓宽了内容的覆盖范围。
- 语言学习与教育Voxtral可以为语言学习者提供一个交互式的练习平台。 学习者可以与模型进行对话,模型能够实时地将语音转为文字并作出回应,甚至可以评估发音的准确性(需要额外开发支持),从而创造一个沉浸式的学习环境。
QA
- Voxtral模型是免费的吗?是的,Voxtral的两个模型(Voxtral Small 24B 和 Voxtral Mini 3B)都是在Apache 2.0许可下发布的开源模型。 这意味着您可以免费下载、使用、修改和分发它们,但需要遵守许可协议的条款。
- 使用Voxtral需要什么样的硬件?Voxtral模型对硬件有一定要求,特别是GPU显存。
Voxtral-Mini-3B-2507在bf16/fp16精度下运行时,大约需要9.5GB的GPU显存。 而更大的Voxtral-Small-24B-2507模型则需要大约55GB的GPU显存,通常需要多张高端GPU才能运行。 - Voxtral支持哪些语言?Voxtral原生支持多种世界主要语言,包括但不限于英语、西班牙语、法语、葡萄牙语、印地语、德语、荷兰语和意大利语。 它还具备自动检测音频语言的能力。
- Voxtral和Whisper模型有什么区别?Voxtral在功能上超越了像Whisper这样的纯语音转录(ASR)模型。 除了高精度的语音转文字,Voxtral还集成了语言理解能力,可以直接对音频内容进行问答、总结和调用外部工具(函数调用),而Whisper主要专注于语音到文本的转换。